type
status
date
slug
summary
tags
category
icon
password
URL

在快速发展的 AI 驱动应用程序格局中,重新排名已成为提高企业搜索结果的准确性和相关性的关键技术。通过使用先进的机器学习算法,重新排名可以优化初始搜索输出,以更好地与用户意图和上下文保持一致,从而显著提高语义搜索的有效性。这通过提供更准确、更符合上下文的结果来提高用户满意度,同时还提高了转化率和参与度指标。
重新排名在优化检索增强生成(Retrieval-Augmented Generation,RAG)流程方面也发挥着至关重要的作用,可确保大型语言模型(Large Language Models,LLMs)处理最相关和高质量的信息。重新排名的这一双重优势(增强语义搜索和RAG流程)使其成为旨在提供卓越搜索体验并在数字市场中保持竞争优势的企业不可或缺的工具。
在本文中,我使用了 NVIDIA NeMo Retriever Reranking NIM。这是一个 transformer 编码器:Mistral-7B 的 LoRA 微调版本,只使用前 16 层以提高吞吐量。解码器模型的最后一个嵌入输出被用作池化策略,并针对排名任务对二进制分类头进行了微调。
什么是 Reranking?
Reranking 是一种复杂的技术,通过使用 LLMs 的高级语言理解能力来增强搜索结果的相关性。
首先,使用传统的信息检索方法(如 BM25 或向量相似度搜索)检索一组候选文档或段落。然后将这些候选文档输入 LLM,该 LLM 分析查询和每个文档之间的语义相关性。LLM 分配相关性分数,从而使文档重新排序以优先处理最相关的文档。
此过程不仅仅是通过关键字匹配来理解查询和文档的上下文和含义,还能显著提高搜索结果的质量。重新排名通常用作初始快速检索步骤后的第二阶段,以确保仅向用户展示最相关的文档。它还可以组合多个数据源的结果,以及集成到 RAG 管道中,以进一步确保上下文适合特定查询。
要访问 NVIDIA NeMo Retriever 集合的世界级信息检索微服务,请参阅 NVIDIA API 目录。
教程预备知识
要充分利用本教程,您需要了解 LLM 推理管线的基本知识以及以下资源:
设置
要开始使用,请使用NVIDIA API 目录并按照以下步骤操作:
- 选择任意型号。
- 选择Python, 获取 API 密钥.
- 将生成的密钥另存为
NVIDIA_API_KEY.
从这里,您应该可以访问端点。
现在,安装 LangChain、NVIDIA AI Endpoints 和 FAISS:
加载相关文档
对于此示例,加载近期关于多模态 LLM 的 NVIDIA 出版物 VILA:视觉语言模型的预训练。使用此单个 PDF 查看博文中的所有示例,但代码可以轻松扩展以加载多个文档。
分割成块
接下来,将文档拆分为单独的块。
请务必注意
chunk_size参数TextSplitter设置正确的数据块大小对于 RAG 性能至关重要,因为 RAG 工作流的成功很大程度上取决于检索步骤如何找到生成所需的正确上下文。检索步骤通常会检查较小的原始文本块,而不是所有文档。整个提示(检索到的数据块加上用户查询)必须符合LLM的上下文窗口。请勿指定数据块的大小太大,并将其与估计的查询大小进行平衡。尝试不同的数据块大小,但典型值应为100-600个令牌,具体取决于LLM。
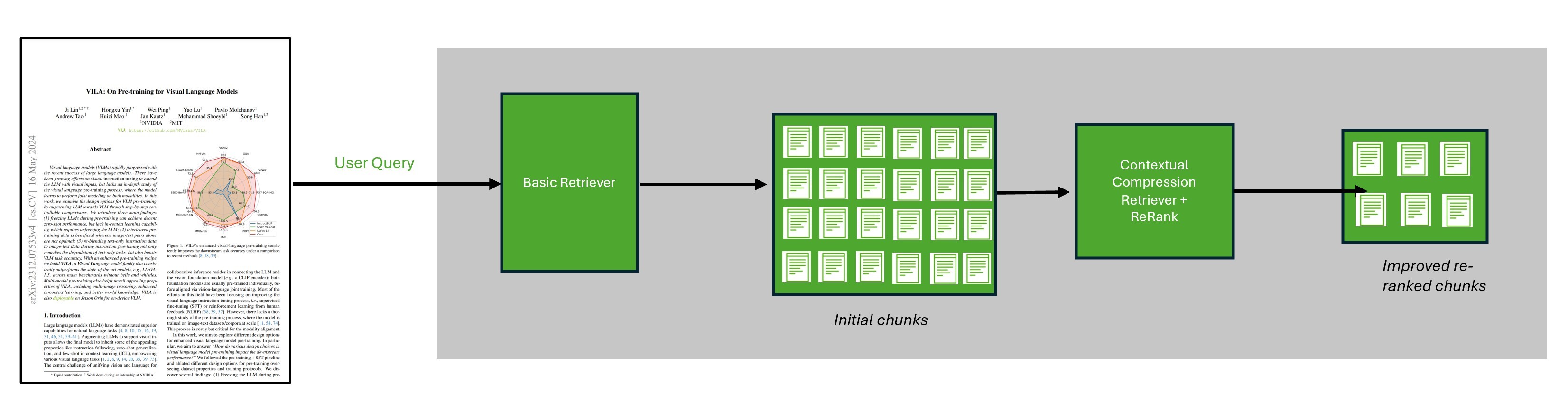
图 1.由 ReRank 增强的搜索系统
生成嵌入
接下来,使用NVIDIA AI 基础端点并将嵌入保存到
/embed以便日后再使用。对于此任务,请使用 FAISS,这是一个用于高效相似性搜索和密集向量聚类的库。它包含的算法可以搜索任意大小的向量集,甚至可能不适合内存的向量集。
创建基本的检索工具
现在,根据文档创建基本检索器,并搜索与您的查询最相关的数据块。此代码基于简单的检索算法输出与您的查询最相关的 45 个数据块。
添加重新排名步骤
现在,我们使用 NeMo Retriever 重新排名 NIM,添加重新排名步骤。这是一个经过优化的 GPU 加速模型,可以提供给定段落包含回答问题信息的概率分数。根据使用相同查询,这将重新排名先前提取的数据块,以确定哪些最相关。
您可以将 NIM 用作 LangChain 上下文压缩检索器的输入,以便通过在返回文档之前根据查询上下文压缩和过滤文档来改进检索。
重新排序的 NIM 会在论文末尾将最相关的块识别为与训练成本相关的段落,其中指定了A100 GPU。
整合多个数据源的结果
除了提高单个数据源的准确性外,您还可以使用重新排名在 RAG 管道中组合多个数据源。
不妨考虑使用来自语义存储(如前面的示例)以及BM25存储的数据的工作流。每个存储都会独立查询,并返回单个存储认为高度相关的结果。要确定结果的整体相关性,需要重新排名。
以下代码示例将先前的语义搜索结果与 BM25 结果相结合。
combined_docs按其与查询的相关性按重新排序的 NIM 进行排序。如需了解更多信息(包括设置 BM25 店),请参阅 /langchain-ai/langchain-nvidia GitHub 库中的完整 Notebook。
连接到 RAG 管道
除了独立使用重新排名之外,您还可以将其添加到 RAG 管道中,以确保管道使用最相关的块来增强原始查询,从而进一步增强响应。
图 2.具有重新排名的增强型 RAG 工作流架构
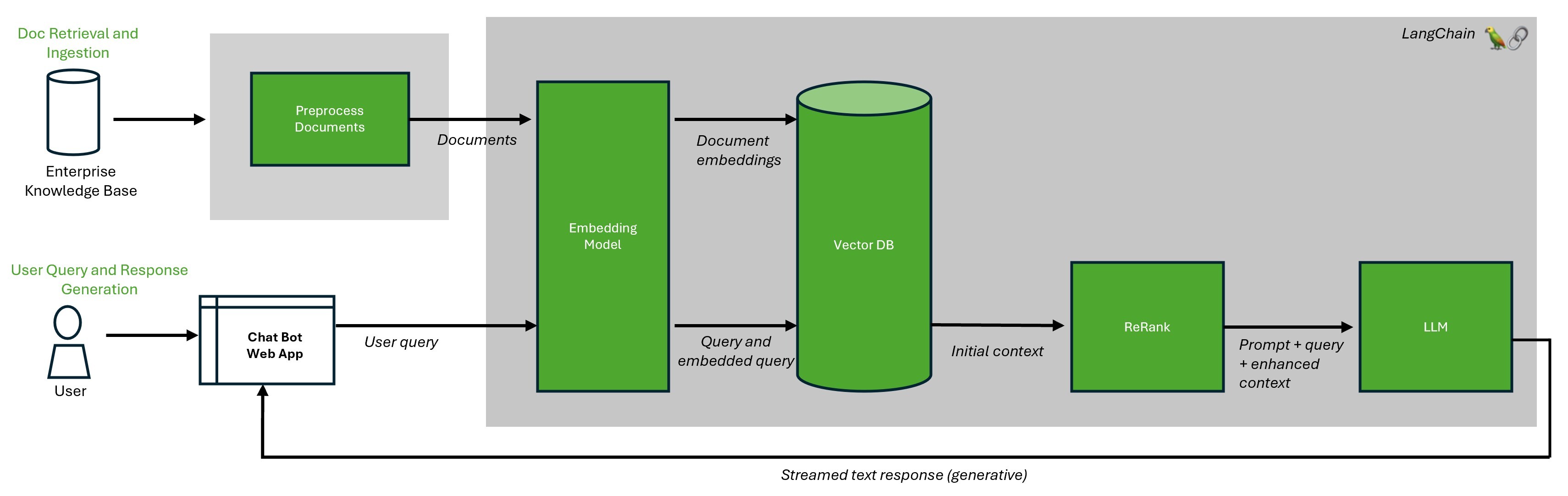
在本例中,连接
compression_retriever上一步到 RAG 管道的对象。RAG 流程现在使用正确的排名靠前的数据块,并总结主要见解:
结束语
RAG 已经成为一种强大的方法,结合了 LLMs 和密集向量表示的优势。通过使用密集向量表示,RAG 模型可以高效扩展,非常适合大型企业应用,如多语言客户服务聊天机器人和代码生成代理等。
随着 LLM 的不断发展,显然 RAG 将在推动创新和提供高质量智能系统方面发挥越来越重要的作用,这些系统可以理解和生成类似人类的语言。
在构建自己的 RAG 工作流时,务必要针对特定内容优化块大小,并选择具有合适上下文长度的 LLM,从而正确地将向量存储文档分割为多个块。在某些情况下,可能需要多个 LLM 的复杂链。要优化 RAG 性能并衡量成功率,请使用一系列可靠的评估器和指标。
有关其他模型和链的更多信息,请参阅NVIDIA AI LangChain 端点.